
Getting a bit sci-fi with image deconstruction

I’m not the first person to note that so much of what’s happening with AI technology right now seems to have been lifted out of any number of dystopian science-fiction novels, where the main takeaways for various CEOs was some version of hey that seems really cool / a really good way to make money as opposed to the cautionary tales they were clearly intended to be.
So while waiting for the imminent announcement of a Department of Precrime, I’ve been busy thinking about what to do with the $25,000 Google gifted me, given that I can’t use it to pay my mortgage. Up to this point, Pixerate has been making heavy use of Together AI’s very generous free APIs for image generation, analysis and general LLM needs. But Google wants me to spend their money and I am happy to oblige.
Naturally I have been playing around with the image (and video) generation capabilities, but it will take me a bit more time to understand the limitations to the extent I do with Flux Schnell, so for now I’ve been focusing on the image analysis part, which is relatively less volatile, but still something that has the potential to create a lot of value to the overall experience.
In a nutshell. when a new image is added to Pixerate through any means, it gets analysed to add a title and description if there wasn’t one already (for example if a user uploads something), but then also to determine the different elements that make up the image. My mental model for this is to think of any image as a Photoshop file, and then try to figure out what are the various “layers” that could have been used to create the final image.
What’s useful about this in practice is that you then have the ability to say well what if I wanted to reverse this– instead of just taking an image or a prompt and adding or removing something to it, could I isolate or “deconstruct” individual elements? The answer of course, is yes.

That is a photograph from Unsplash, with generative AI figuring out what’s in it and then how to recreate some aspect of it in isolation. From the user’s perspective, they upload the image, click a button to see what elements were found, and then choose the ones they want to extract and iterate on.
This has been a feature that has been in Pixerate for a while, but there was one thing that Google Gemini does that made this into the feature I really wanted was its ability to figure out not just what is in the image but where in the image each thing was. Which meant I could go full sci-fi, and do this:
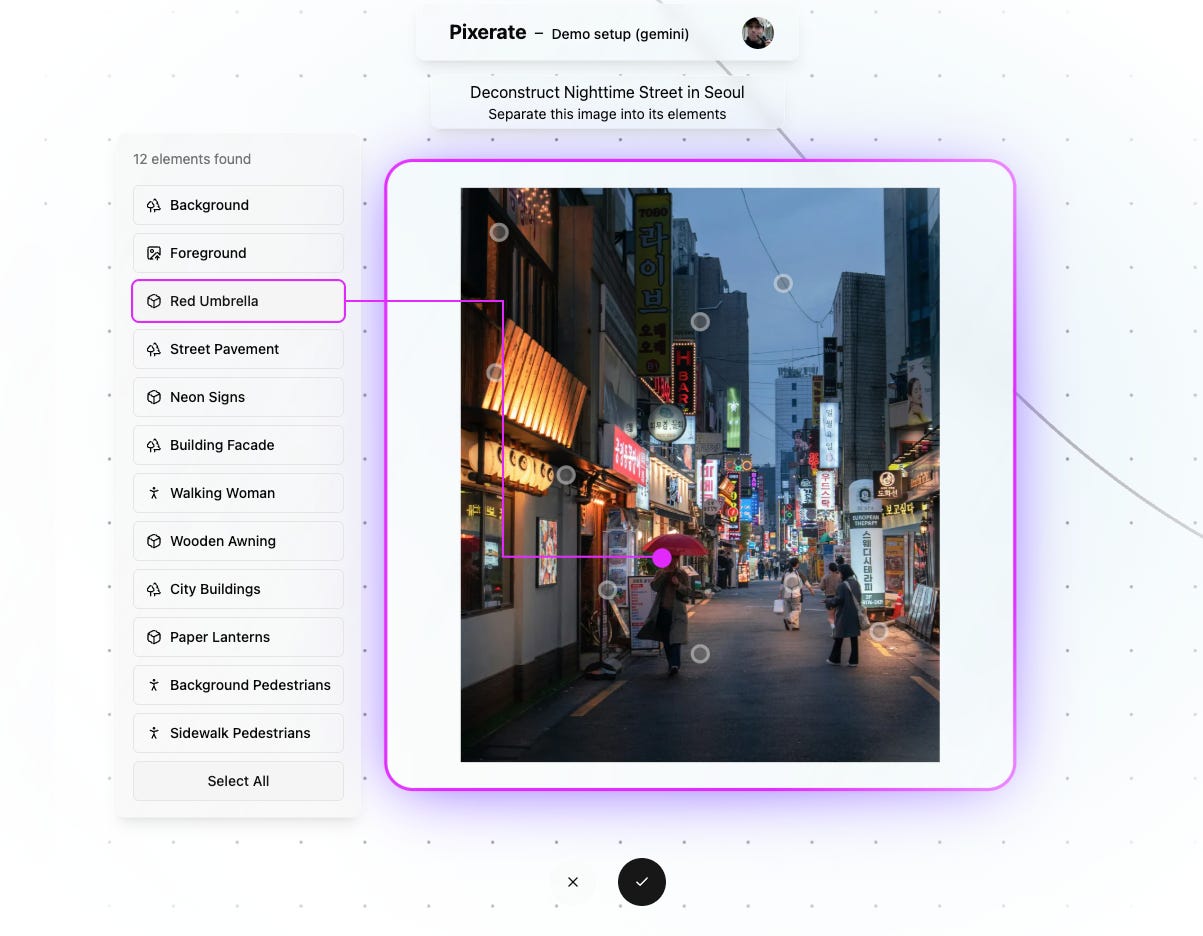
Instead of just having a list of things that were found in the image, there’s a visible connection between those things and the image itself. In terms of pure capability, not much has changed, but it feels very different to use.
Actually creating the code to make it all work proved to be a nightmare. Gemini outputs bounding boxes for things that it finds, which it gives you as coordinates as a percentage of the image. This is actually fine (well, I’ll get to the discrepancies there in a moment), but trying to cobble together the CSS to overlay them precisely on the image proved to be almost impossible because: (a) images are of arbitrary size, (b) they are of arbitrary aspect ratio, (c) the container they are in is also of an arbitrary size and aspect ratio. The images themselves display just fine, within the bounds of the container, without getting stretched or cropped. But working on this it seemed like I had somehow stumbled across the only possible combination of CSS and HTML that allowed the images to display correctly, because anything I changed immediately broke everything.
So what this all meant was that I could overlay the bounding boxes on the image perfectly, unless the image wasn’t square, and wasn’t repositioned, and didn’t change its size ever. And of course none of these things were true because I love animating everything in the UI as much as possible.
So after a day of doing the sort of maths that make my head hurt, and after asking every flavour of LLM how to make it work (unsuccessfully), I finally landed on a combination of javascript and CSS that at least positioned everything correctly (and which I will hopefully never touch again).
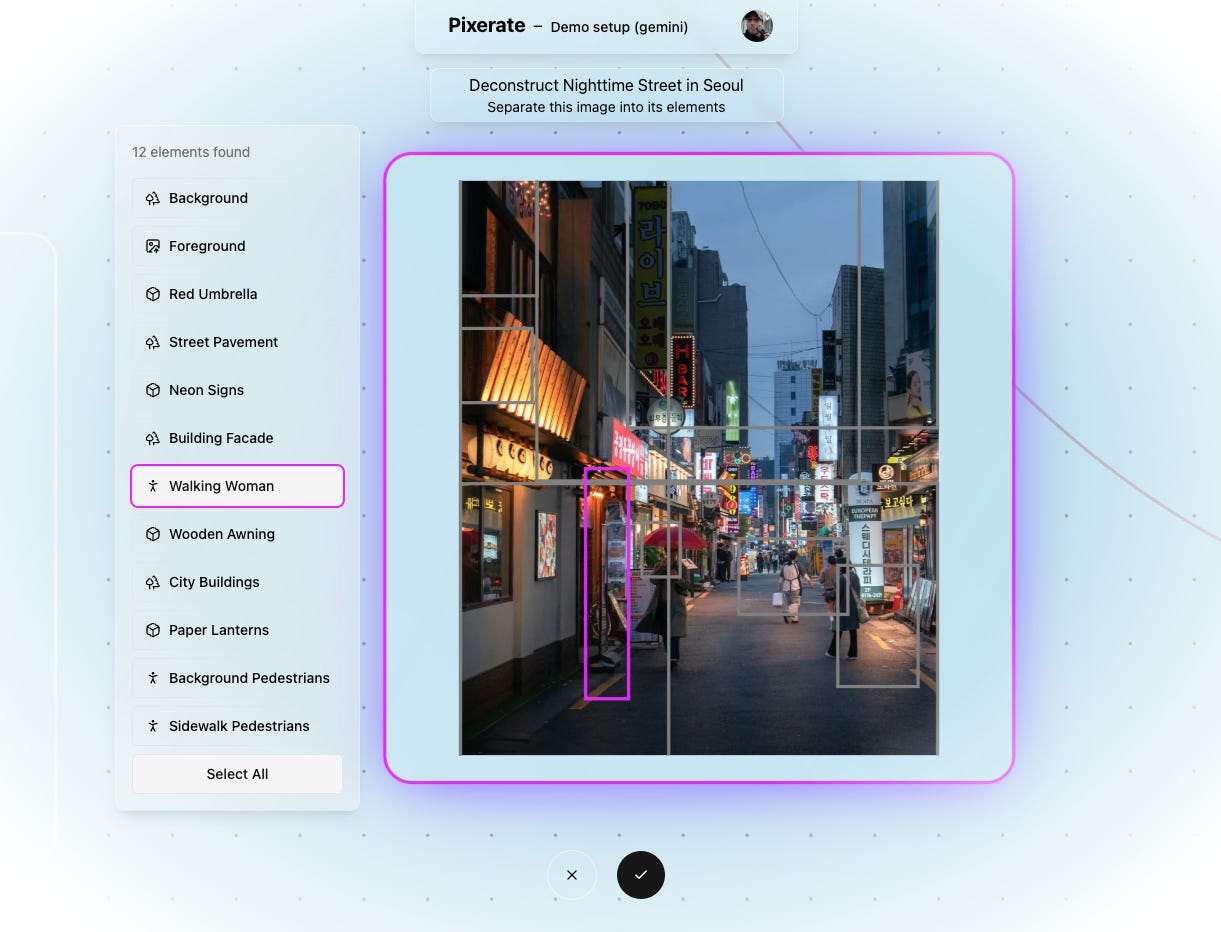
The major complication in all of this is that actually the bounding boxes that Gemini produces don’t actually seem to be correct in some cases, as can be seen above. I don’t know why this is, I checked my calculations and they seem right, then I also tested by just running the same query with the same image over and over and getting different results each time. So the implementation here is far from perfect.
But on the plus side, these issues are much more pronounced when rendering the boxes, because I’m only drawing points (I think they look much cleaner than the boxes), it’s not as noticeable. Good enough that I can now move onto the next thing.
I'm working on Pixerate, software that helps art directors experiment and iterate rapidly. If that resonates with you, I'd love to hear from you!